Hello Dear Reader! It's been a while. I was working with a friend and we came across an interesting problem. They had a large amount of skewness/data skew. This led to some performance issues for them. The way this manifested itself was in a set of queries that ran quickly, normally within seconds. Then occasionally they ran much longer. To be precise, they ran about x800 times longer.
As you can imagine this is a less than ideal situation for a production environment. Their solution was to add OPTION (RECOMPILE) to all of their stored procedures. This solved the issue with their data skew. It caused additional side effects. Increased CPU as every stored procedure now had to recompile before execution. No stored procedure could experience plan reuse. Using DMV's to track stored procedure utilization and statistics no longer worked.
"So Balls", you say, "What is the alternative? Is there an alternative? And what in the name of King and Country is skewness/data skew!"
Ahh great question Dear Reader! Dear Reader why are you English today?
"Because you watched the Imitation Game last night, and Benedict Cumberbatch's voice is still stuck in your head."
Right as always Dear Reader! Good point let's explain it and then do a Demo!
SKEWNESS/DATA SKEW
 Skewness is a term from statistics and probability theory that refers to the asymmetry on the probability distribution of a real valued random variable about its mean. This could get complicated quickly. In simpler terms that I can understand it means that there are patterns based on variables with an assigned real value. Based on those variables skewness can be determined and it is the
Skewness is a term from statistics and probability theory that refers to the asymmetry on the probability distribution of a real valued random variable about its mean. This could get complicated quickly. In simpler terms that I can understand it means that there are patterns based on variables with an assigned real value. Based on those variables skewness can be determined and it is the
difference of the normal.
How does this effect our query plans. With data skew we have a over abundance of data that fits one statistical model and it does not fit for others. This means the way the SQL Server Cardinality Estimator estimates for one may be different for another based on statistics.
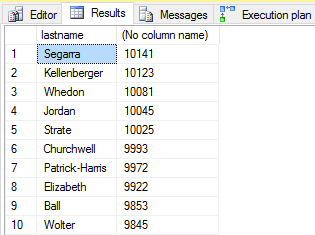
Here's a quick example. I have a school with 100,000 students. Every student has a combination of 10 different last names. On average one could assume that every 10,000 students will have different last names. If we randomly assign these values, there will be a slight skewness. Most of the ranges will be similar. For this example I'll use my students table from my college database.
order by count(*) desc;
Now we move a new student to the area. This one student will give us quite a bit of data skew, and will be extremely asymmetrical to the other results.
In order to show this in action we'll make a stored procedure that returns our First Name, Last Name, and the Course Name of students by last name. Remember some students will have multiple courses. This means we will have more results than we do last names.
if exists(select name from sys.procedures where name='p_sel_get_stu_name') drop procedure p_sel_get_stu_name create procedure p_sel_get_stu_name(@lname varchar(50)) on s.studentID=e.studentid on e.courseid = c.courseid lastname=@lname
end
So now we will execute this query and see the difference between our query plans and benchmark the performance.
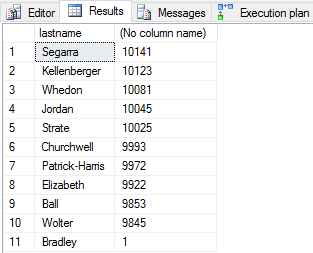
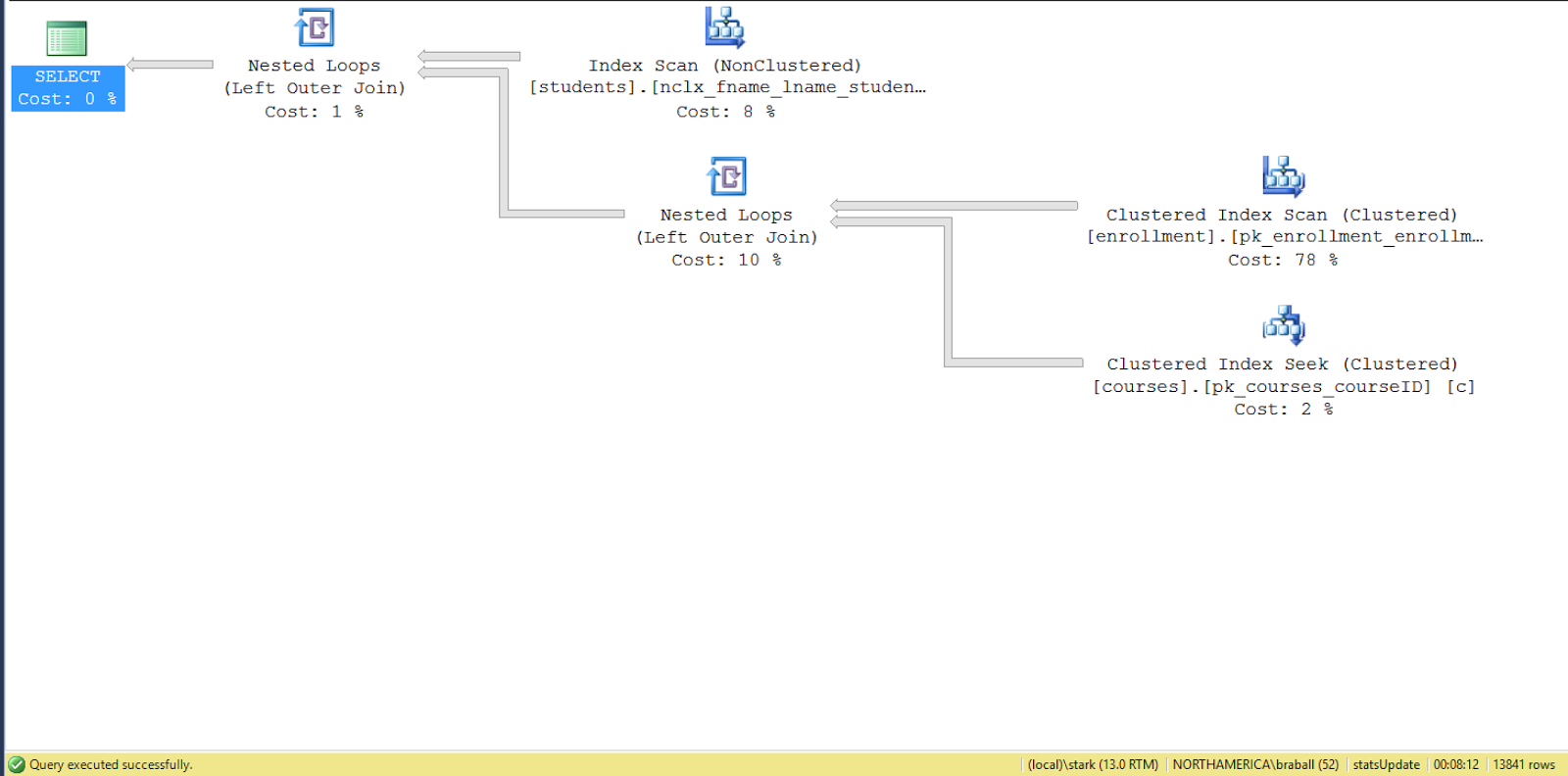
exec p_sel_get_stu_name'Bradley' with recompile;
exec p_sel_get_stu_name 'Segarra' with recompile;
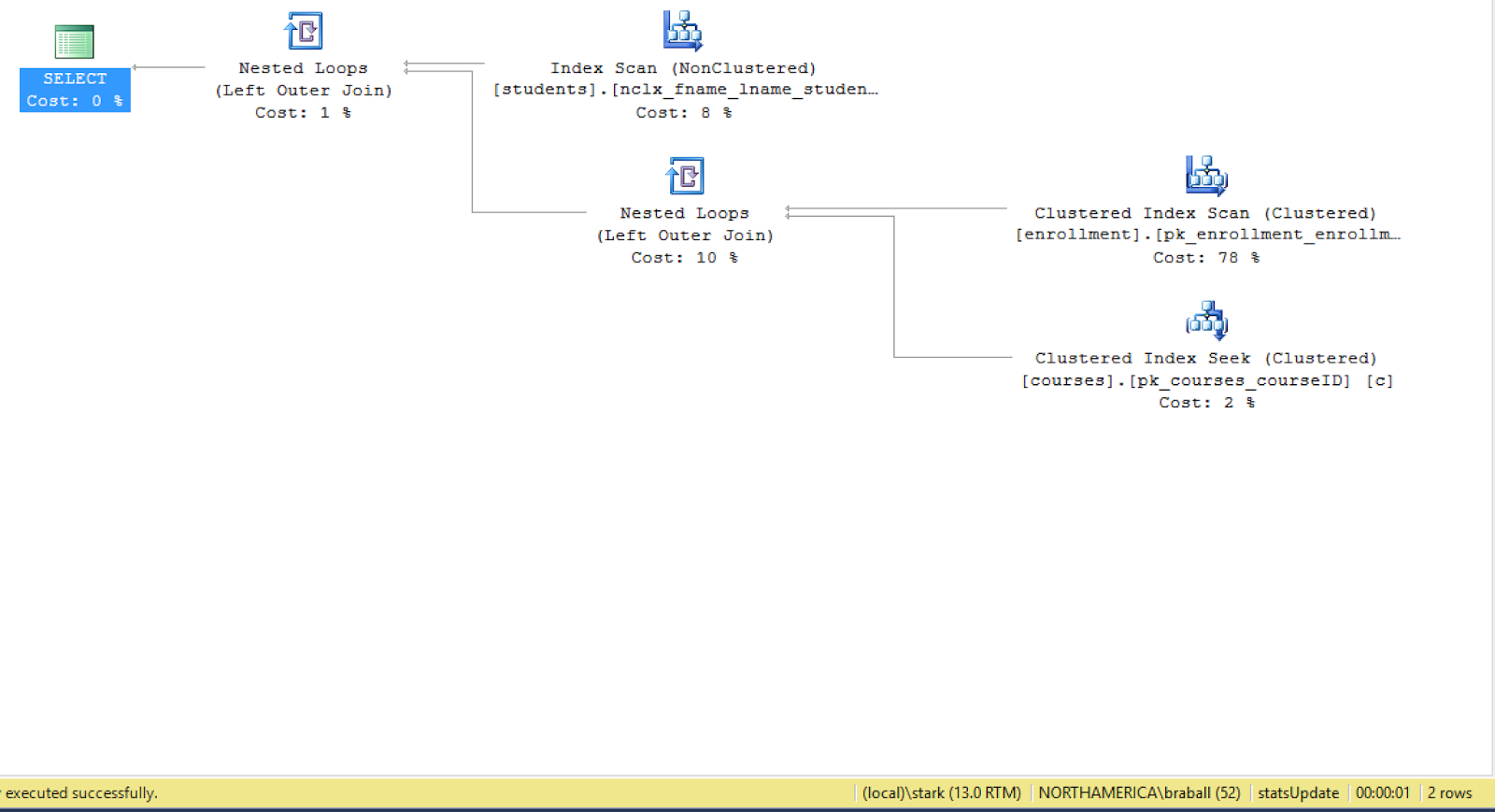
The first query took a little over a second to return two rows. The second query was sub-second and returned 13,843 rows. Each execution plan was different. One was parallel, the other was serial. That makes sense Parallel returned over 13,000 rows, serial only returned 2 row. The statistical variance is different. The cardinality estimate gave us different results.
Now let's make this bad. I'm going to run the first query and second query again. This time I'm removing the with recompile.
exec p_sel_get_stu_name'Bradley'; exec p_sel_get_stu_name 'Segarra';
The first query did not change. The second one did.
We used the cached plan. Because of data skew we forced 13,843 rows through the serial execution plan. The result was 8 minutes and 42 seconds instead of a sub-second query.
This is data skew. We've shown that recompiling the query forces both to execute with their least cost plan. Is there another option? In this case we could use the query hint OPTIMIZE FOR UNKNOWN.
The benefit of OPTIMIZE FOR UNKNOWN is that we can remove the recompile. This will allow us to get the best/least cost plan based on data skewness of the statistics.
if exists(select name from sys.procedures where name='p_sel_get_stu_name') drop procedure p_sel_get_stu_name create procedure p_sel_get_stu_name(@lname varchar(50)) on s.studentID=e.studentid on e.courseid = c.courseid option (optimize for unknown) end
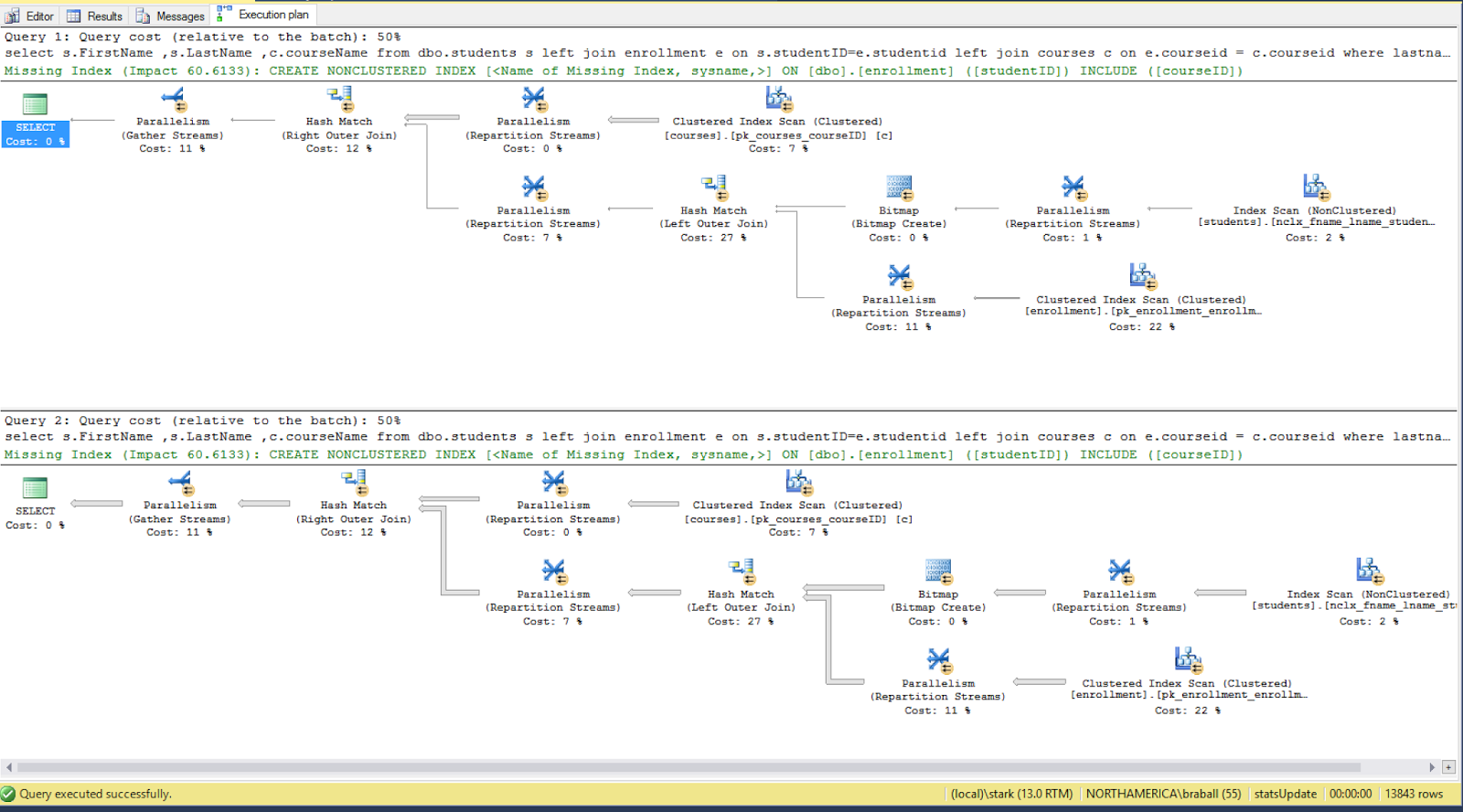
exec p_sel_get_stu_name 'Bradley';
exec p_sel_get_stu_name 'Segarra';
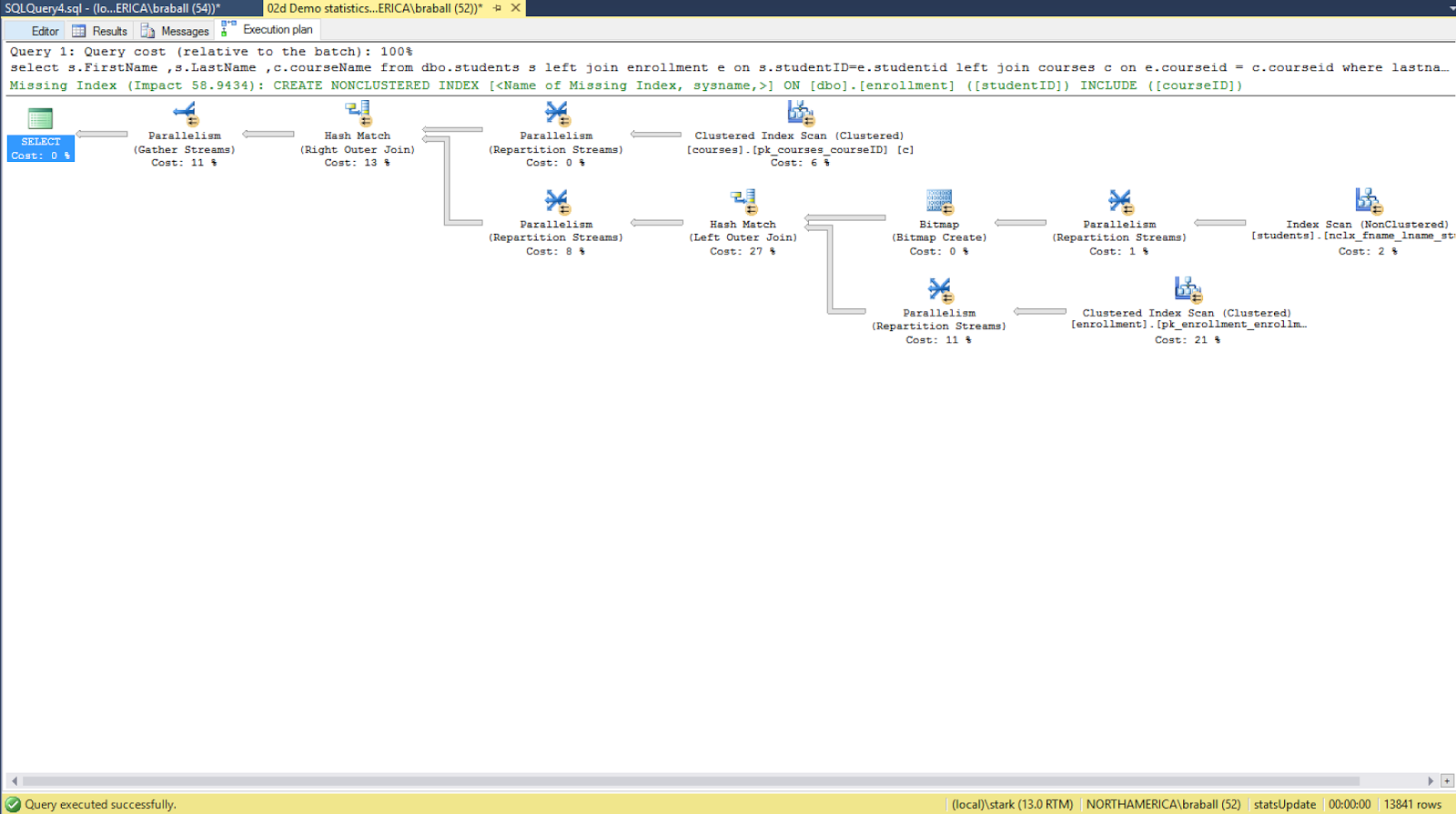
Now we execute our procedures and we get our execution plans. Here are our new query plans.
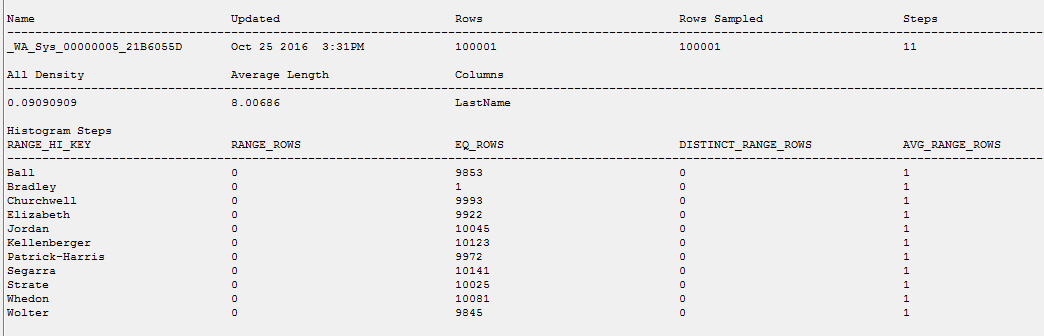
You'll notice that the execution plan based on statistical variance was parallel plan. Both queries executed sub-second. This is not the least cost plan for the first query. In case you were curious here is a look at the histogram.
WRAP IT UP
So what does this mean? For the business purpose of speeding up a query option recompile is completely valid.
It comes at a cost. Recompilations, increased CPU utilization, and you loose the history of the execution of the stored procedure from DMVs.
If those costs do not effect you, or effect the system less than the fluctuation of query performance then it is valid.
There is also another alternative to use in your tool belt. That is what we used today. Like all things in computers use it judiciously. Test, test, and retest before deploying into production. As always Dear Reader, Thanks for stopping by.
Thanks,
Brad


 Skewness is a term from statistics and probability theory that refers to the asymmetry on the probability distribution of a real valued random variable about its mean. This could get complicated quickly. In simpler terms that I can understand it means that there are patterns based on variables with an assigned real value. Based on those variables skewness can be determined and it is the
Skewness is a term from statistics and probability theory that refers to the asymmetry on the probability distribution of a real valued random variable about its mean. This could get complicated quickly. In simpler terms that I can understand it means that there are patterns based on variables with an assigned real value. Based on those variables skewness can be determined and it is the